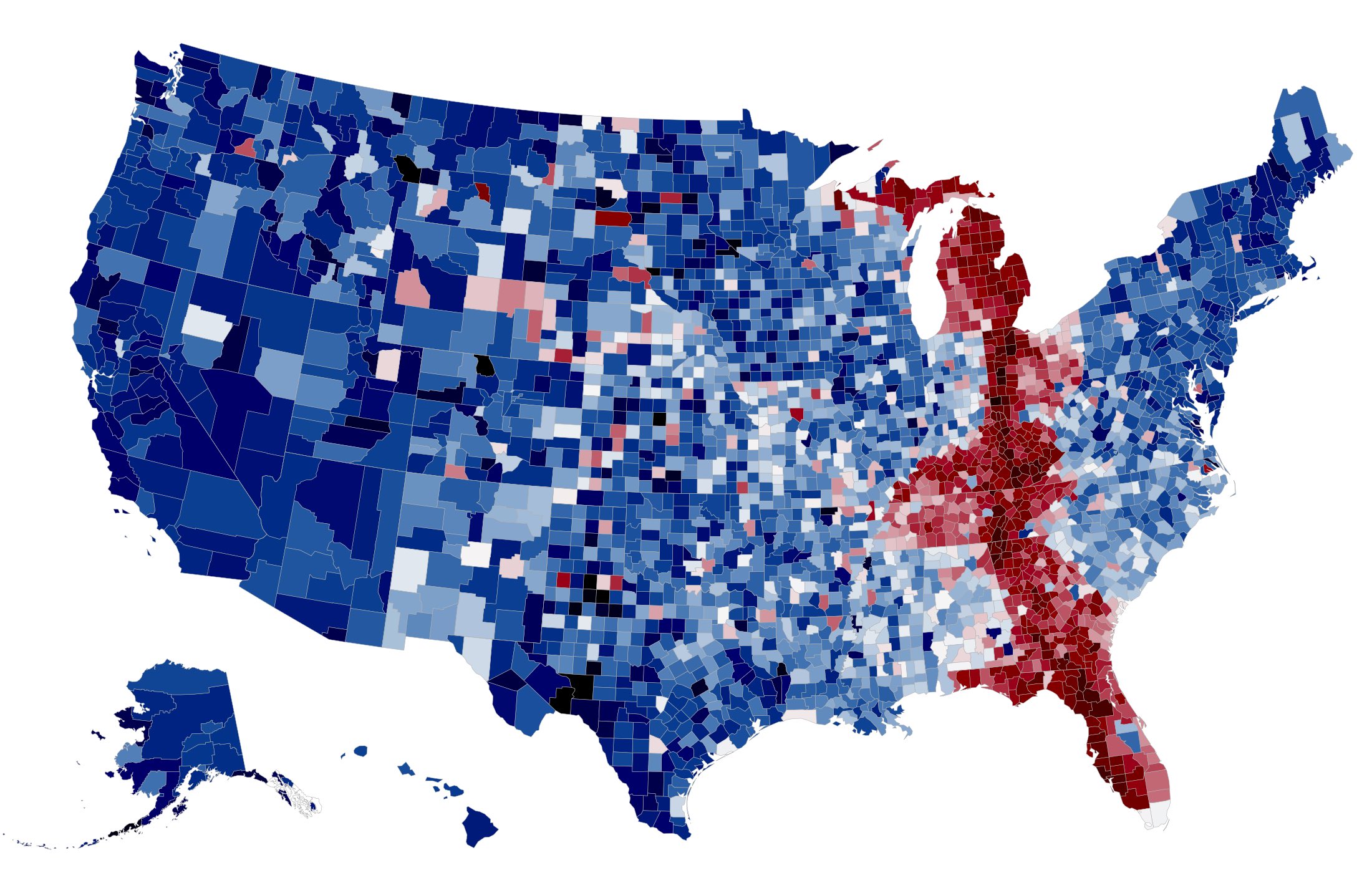
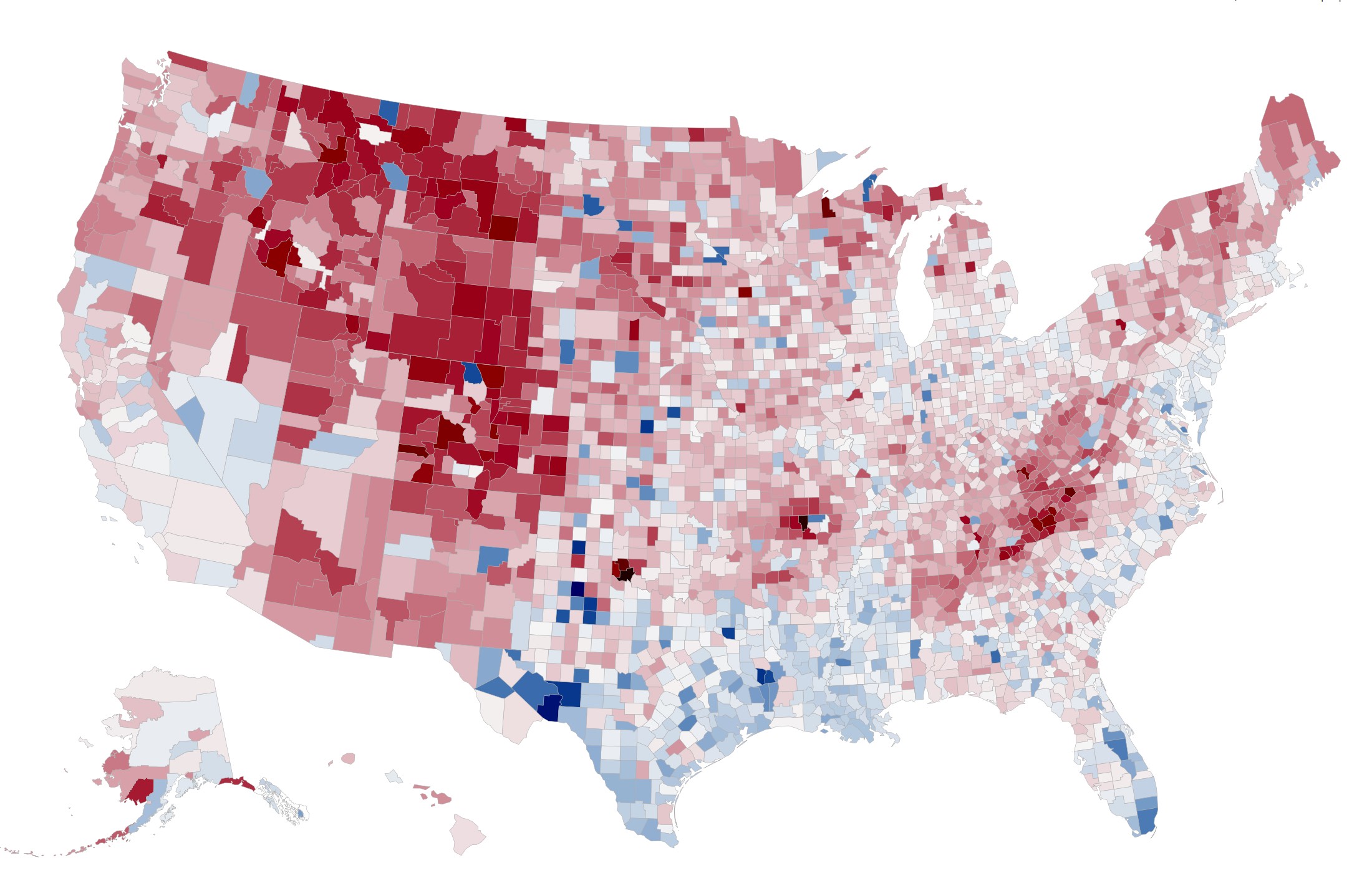
About the project
This project allows us to explore Twitter word usage. The data for this project comes from a data set of over 111 billion tweets created between 2006 and 2015. We restrict our study to only to tweets where the user's listed location is within the United States (approximately 20-30% of all tweets). We generate a "location index" using geo-tagged tweets, mapping users' self-reported locations to a distribution over U.S. counties using approximately 453 million geo-tags. Then, this index allows us to map word usage for tweets with a self-reported location, but without geo-tags.
We tokenize these tweets using
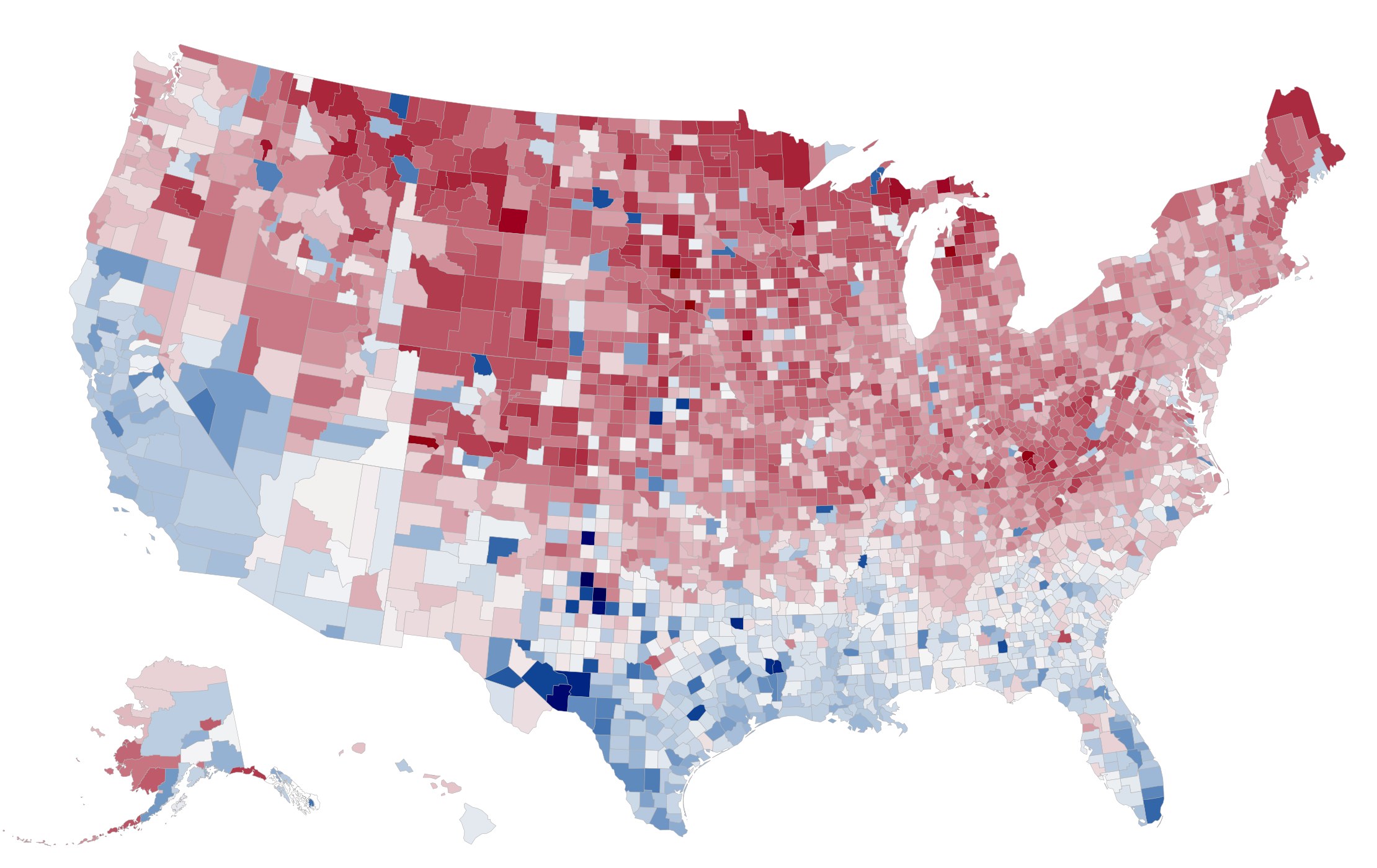
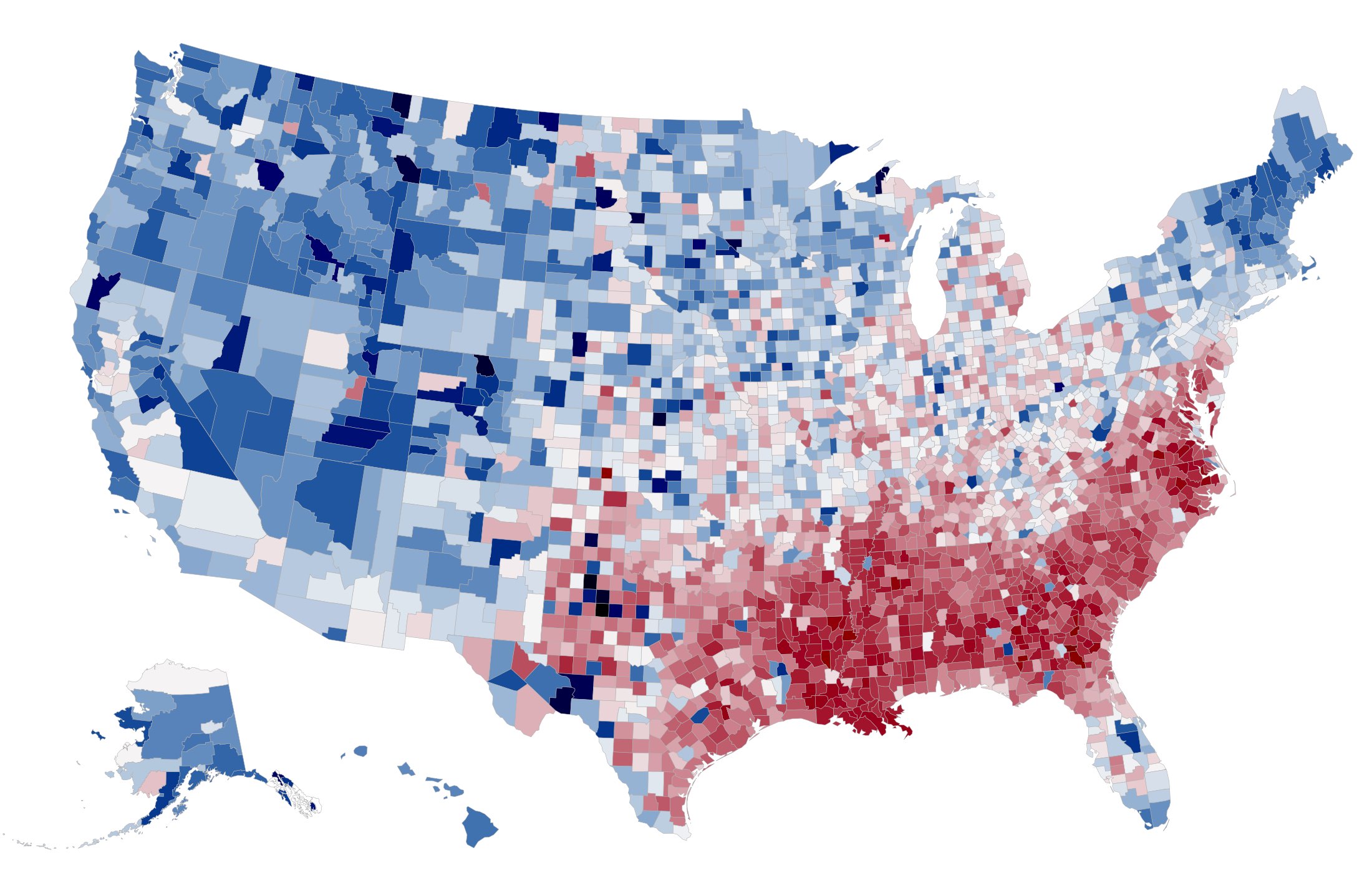
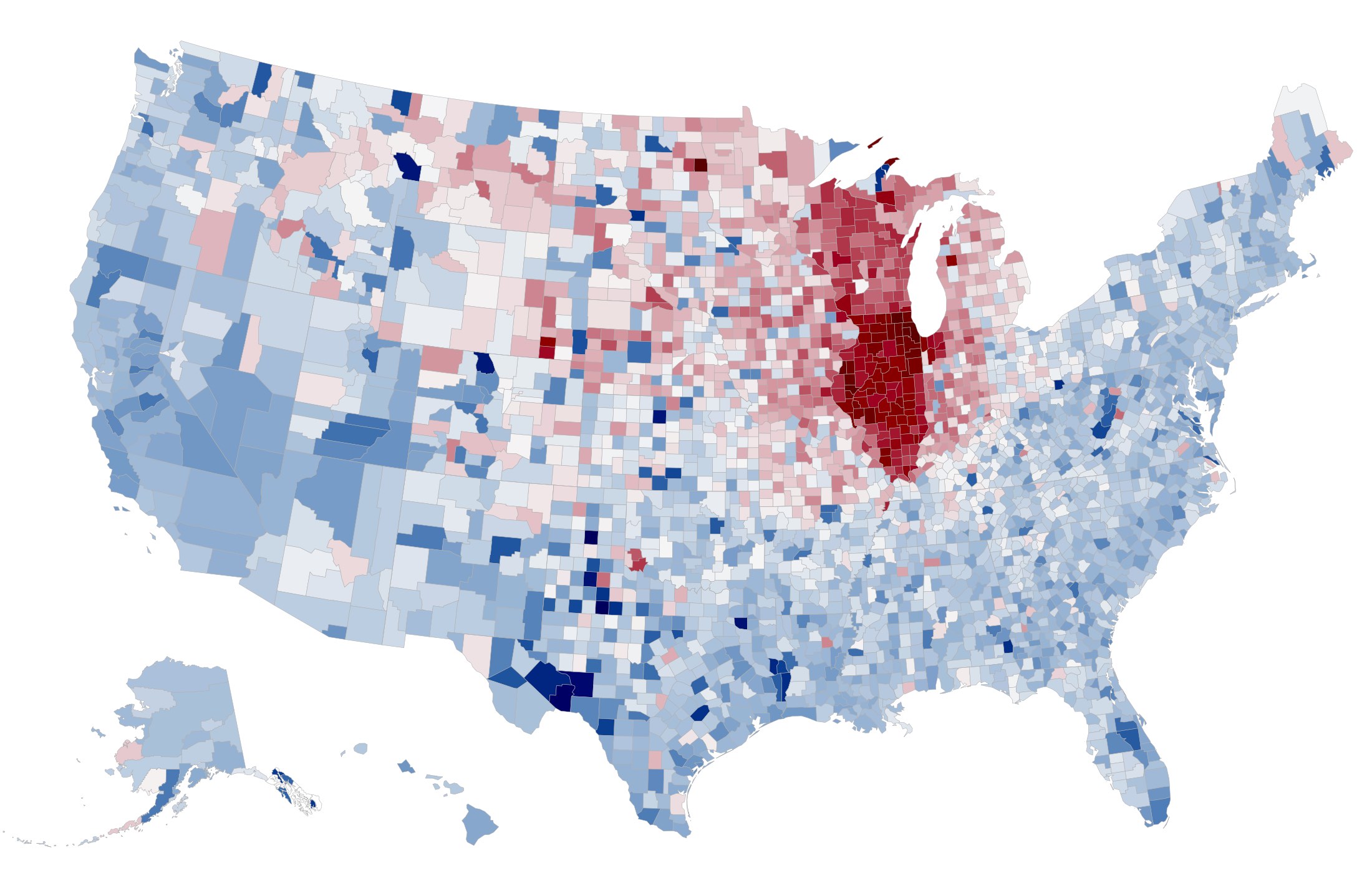
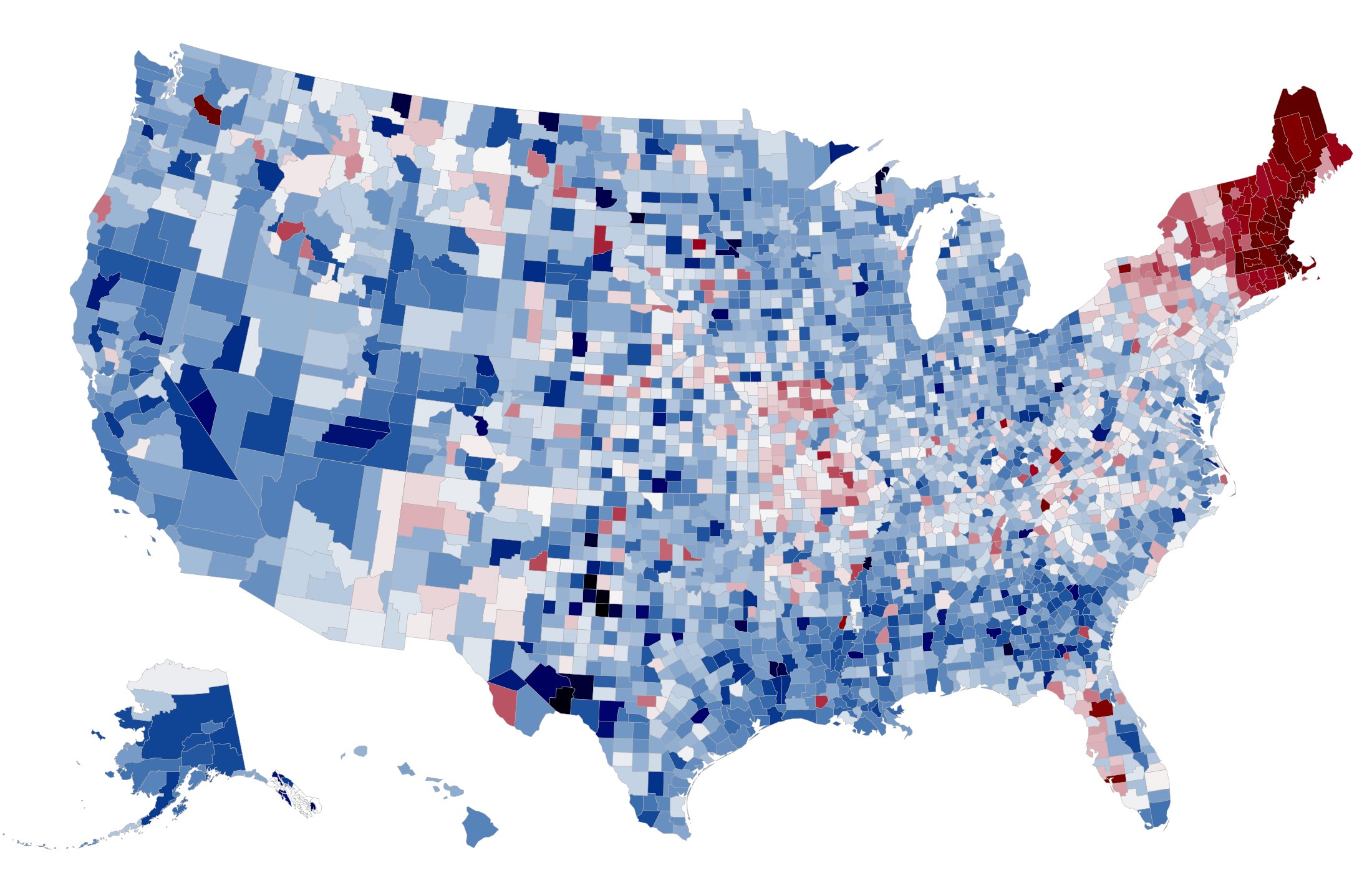
twokenize, and then map the tweets into U.S. counties using the location index. For each of the most popular 100,000 tokens, we determine the overall national frequency of that token and the per-county frequency. The map shows the relationship between these two frequencies: if a word is used more frequently in a county than the national average, that county is colored red; if it is used less frequently, it is colored blue.
You can try different words
at the search page. A few of our favorite images are below:
A few additional examples of words to search for include:
- Weather terms: tornado, hail, blizzard, sleet, ...
- Geographic terms: beach, lake, ...
- State names and abbreviations: fl, ny, id, texas, ...
- Regional slang: wicked, hella, da, ...
- Sports teams: patriots, giants, ...
About the researchers
This project is a collaboration between
Sune Lehmann at the Danish Technical University,
Anders Søgaard at
University of Copenhagen, Bjarke Felbo at the Danish Technical University, and
Alan Mislove at Northeastern University (currently on sabbatical at
the University of Copenhagen).